2020.09.09-2020.09.10
文献阅读——联邦学习鲁棒性
- 上一篇文献阅读主要解决了如何构建联邦学习模型
- 这一篇文献阅读主要解决联邦学习模型中的问题。包括:
- 模型的鲁棒性和安全性问题。(恶意攻击和破坏)
- 非独立同分布数据提高准确性、有效性和训练速度
- 数据的隐私保护为题。(隐私保护)
- 去中心化的联邦学习与模型共享。(在完全对称的联邦学习中的激励机制。)区块链联邦学习,通过区块链交换和验证设备。
1 模型攻击:鲁棒性联邦学习研究的最新进展
问题提出
- 机器学习受到各种对抗攻击。包括数据和模型更新过程中的中毒、模型规避、模型窃取、对用户的私人训练数据进行数据推理攻击。
- 可以分为两大类
- 定向攻击:对特定类型的样本准确性丢失。后门攻击(Backdoor Attacks),在主要任务中保持较好的性能,在次要任务中表现较差的性能。
- 非定向攻击:破坏模型整体准确性
- 模型攻击:被攻击的客户端改变本地模型的更新,从而改变全局模型。
- 数据攻击:以改变所有训练样本中的一个子集,从而改变全局模型。
解决方案
- 安全聚合协议 (Secure Aggregation,SecAgg):确保服务器无法检查每个用户的更新。
2 How To Backdoor Federated Learning——机器之心
联邦学习模型
$$
L^i-第i轮本地训练模型\
G^i-第i轮联邦训练模型\
l-损失函数 \
epoch-训练集合\
batch-数据集合\
\eta-单次学习率\
m-随机选择的参与者\
$$
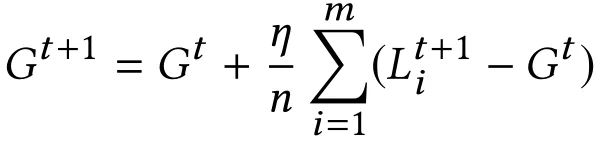
联邦学习攻击概述
- 攻击者:控制了一个或者几个参与者,包括本地数据和本地训练过程。
- 攻击目标:攻击者希望通过联邦学习得到一个联合模型,该模型在其主任务和攻击者选择的后门子任务上都能实现高准确度,并且在攻击后的多轮攻击后,在后门子任务上保持高准确度。
- 语义后门:修改样本的数据特征。
- 基线攻击:在每个训练批次中尽量包括正确标记的输入和后门输入的混合,以帮助模型学习识别二者的差异。但中央服务器的聚合操作抵消了后门模型的大部分贡献,
- 模型替换攻击:对后门模型的权重进行放大,抵消原来的模型。
- 改善持久性并规避异常检查。
3 Can You Really Backdoor Federated Learning?
4 Local Model Poisoning Attacks to Byzantine-Robust Federated Learning
5 Federated Variance-Reduced Stochastic Gradient Descent with Robustness to Byzantine Attacks
6 怎么通过梯度信息还原训练数据?
文献阅读——联邦学习隐私安全性
文献阅读——联邦学习效率问题
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Estom的博客!
相关推荐

2020-01-13
2020.01.01-2020.01.31
1 自适应动态调整粒子群的云计算任务调度内容 粒子群算法 DPSO动态粒子群算法 基于自适应动态调整权重系数 基于进化信息调整分数阶次 基于 Levy 飞行特征的局部最优 多目标构造成单一目标。 对云计算模型进行抽象。得到数学模型。转换为数学问题。 对任务调度的目标和约束进行描述。 给出了粒子群算法的数学描述 实验对比了各种算法。 2 基于离散粒子群优化的云计算 QoS 调度算法 是一种多约束的任务调度算法。 给出了一个任务调度模型(重要) 将多个约束进行归一化描述。 不具有动态扩展的能力。 3 云计算资源调度研究及改进 给出任务调度模型(包含对任务、资源的抽象) 给出了任务调度的目标 给出了任务调度的算法 我觉得接下来我应该从这三个方面论述。 4 基于遗传算法的柔性资源调度优化方法研究 系统的讲述资源调度问题的分类和细节。十分值得借鉴。也就是将当前的任务使用他给出的任务调度领域的基本概念进行讲解。 柔性资源调度问题(原子任务的选择柔性机器)与本次的任务目标一致。 非常重要写方案的时候可以参考。 5 基于异构计算系统中动态任务分配的蜂群算法研究 给...

2021-09-07
9.0-chinese
第9章 高级线程管理本章主要内容 线程池 处理线程池中任务的依赖关系 池中线程如何获取任务 中断线程 之前的章节中,我们通过创建std::thread对象来对线程进行管理。在一些情况下,这种方式不可行了,因为需要在线程的整个生命周期中对其进行管理,并根据硬件来确定线程数量,等等。理想情况是将代码划分为最小块,再并发执行,之后交给处理器和标准库,进行性能优化。 另一种情况是,当使用多线程来解决某个问题时,在某个条件达成的时候,可以提前结束。可能是因为结果已经确定,或者因为产生错误,亦或是用户执行终止操作。无论是哪种原因,线程都需要发送“请停止”请求,放弃任务,清理,然后尽快停止。 本章,我们将了解一下管理线程和任务的机制,从自动管理线程数量和自动管理任务划分开始。
2024-05-13
03 Pipelines原理
****## Kubeflow Pipelines 1 PipeLines介绍安装教程https://cloud.tencent.com/developer/article/1674948 使用教程https://juejin.cn/post/6844904195301064712 详细说明 https://blog.csdn.net/qq_45808700/article/details/132188234 1.1 Kubeflow Pipelines介绍kubeflow/kubeflow 是一个胶水项目,pipelines 是基于 kubeflow 实现的工作流系统,它的目标是借助 kubeflow 的底层支持,实现出一套工作流,支持数据准备,模型训练,模型部署,可以通过代码提交等等方式触发 Kubeflow 是一个基于云原生的Machine Learning Platform,它把诸多对机器学习的支持,比如模型训练,超参数训练,模型部署等等结合在了一起,部署了 kubeflow 用户就可以利用它进行不同的机器学习任务,旨于快速在kubernetes环境中构建一套开...

2020-10-07
04多元线性回归
多元线性回归问题 假设函数 $$h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x+\theta_3x+\theta_4x\= [\theta_0,\theta_1,\theta_2,\theta_3,\theta_4]\times[1,x_1,x_2,x_3,x_4]^T\=\overrightarrow{\theta}^T\times\overrightarrow{x}$$ 代价函数 $$J(\overrightarrow{\theta})=\frac{1}{2m}\sum_{i=1}^m(h_\theta(\overrightarrow{x}^{(i)})-y^{(i)})^2$$ 梯度下降 $$\theta_j = \theta_j - \alpha\frac{\partial}{\partial\theta_j}J(\overrightarrow{\theta})$$ 特征放缩(归一化处理)当一个假设函数的多个特征处在相同的范围的时候,函数会更快的收敛。 均值归一化...
2020-10-28
02机器学习(ML)策略(2)
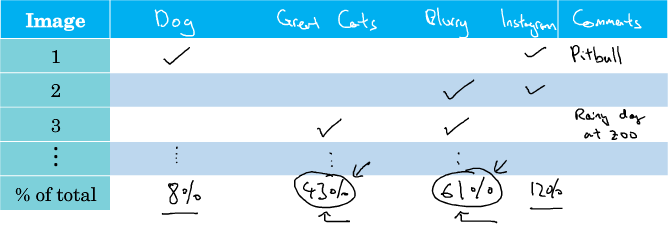
机器学习(ML)策略(2)错误分析 通过人工检查机器学习模型得出的结果中出现的一些错误,有助于深入了解下一步要进行的工作。这个过程被称作错误分析(Error Analysis)。 例如,你可能会发现一个猫图片识别器错误地将一些看上去像猫的狗误识别为猫。这时,立即盲目地去研究一个能够精确识别出狗的算法不一定是最好的选择,因为我们不知道这样做会对提高分类器的准确率有多大的帮助。 这时,我们可以从分类错误的样本中统计出狗的样本数量。根据狗样本所占的比重来判断这一问题的重要性。假如狗类样本所占比重仅为 5%,那么即使花费几个月的时间来提升模型对狗的识别率,改进后的模型错误率并没有显著改善;而如果错误样本中狗类所占比重为 50%,那么改进后的模型性能会有较大的提升。因此,花费更多的时间去研究能够精确识别出狗的算法是值得的。 这种人工检查看似简单而愚笨,但却是十分必要的,因为这项工作能够有效避免花费大量的时间与精力去做一些对提高模型性能收效甚微的工作,让我们专注于解决影响模型准确率的主要问题。 在对输出结果中分类错误的样本进行人工分析时,可以建立一个表格来记录每一个分类错误的具体信息...
2021-03-20
54
监督学习:从高维观察预测输出变量校验者: @Kyrie @片刻 @Loopy @N!no翻译者: @森系 监督学习解决的问题 监督学习 在于学习两个数据集的联系:观察数据 X 和我们正在尝试预测的额外变量 y (通常称“目标”或“标签”), 而且通常是长度为 n_samples 的一维数组。 scikit-learn 中所有监督的估计量 都有一个用来拟合模型的 fit(X, y) 方法,和根据给定的没有标签观察值 X 返回预测的带标签的 y 的 predict(X) 方法。 词汇:分类和回归 如果预测任务是为了将观察值分类到有限的标签集合中,换句话说,就是给观察对象命名,那任务就被称为 分类 任务。另外,如果任务是为了预测一个连续的目标变量,那就被称为 回归 任务。 当在 scikit-learn 中进行分类时,y 是一个整数或字符型的向量。 注:可以查看用 scikit-learn 进行机器学习介绍 快速了解机器学习中的基础词汇。 最近邻和维度惩罚 鸢尾属植物分类 鸢尾属植物数据集是根据花瓣长度...